
OCI(Oracle Cloud Infrastructures)の強力な無料枠は周知だと思う。
86系CPUのVMが2インスタンス使える、これは1/8OCPU+1GBメモリ/インスタンスって言うので、まぁGCPの無料のMicroインスタンスと同程度と考えればOKなヤツ。 これ自体も2インスタンスだし、メモリもやや多いって言うのはあるんだけど、最強なのがAmpereインスタンス(ARM)
(178)
OCI(Oracle Cloud Infrastructures)の強力な無料枠は周知だと思う。
86系CPUのVMが2インスタンス使える、これは1/8OCPU+1GBメモリ/インスタンスって言うので、まぁGCPの無料のMicroインスタンスと同程度と考えればOKなヤツ。 これ自体も2インスタンスだし、メモリもやや多いって言うのはあるんだけど、最強なのがAmpereインスタンス(ARM)
(178)
Pythonでスピードを上げるためにjoblibを使うけど、並列度を設定するn_jobsを盲目的に自動の-1に設定してることが多い気がするけど、これはケースによっては全くおいしくないという話。
(118)
個人サーバでメールサーバを構築していると迷惑メールがわんさか飛んでくる。
一般的な商用サービスならブラックリストサービスを活用してブロックして防いでいるけど、基本設定だけの個人サービスだとわんさか飛んでくる。 コレを防ぐには、RBL=リアルタイムブラックリストのフリーなヤツを用いて送信元などを確認して自動でブロックする方法がある。 しかし、大手のSpamhausはさくらインターネットをブロックした(商用なのに無料利用しているヤツがいたための対策)
しかし、ちゃんと非商用ユーザのための道は残されていて、アカウントを取得して専用のキー付アドレスを使えば良い。
以下アドレスで登録を行う、フリートライアルとなっているけど、非商用は普通にそのまま使える。
https://www.spamhaus.com/free-trial/sign-up-for-a-free-data-query-service-account
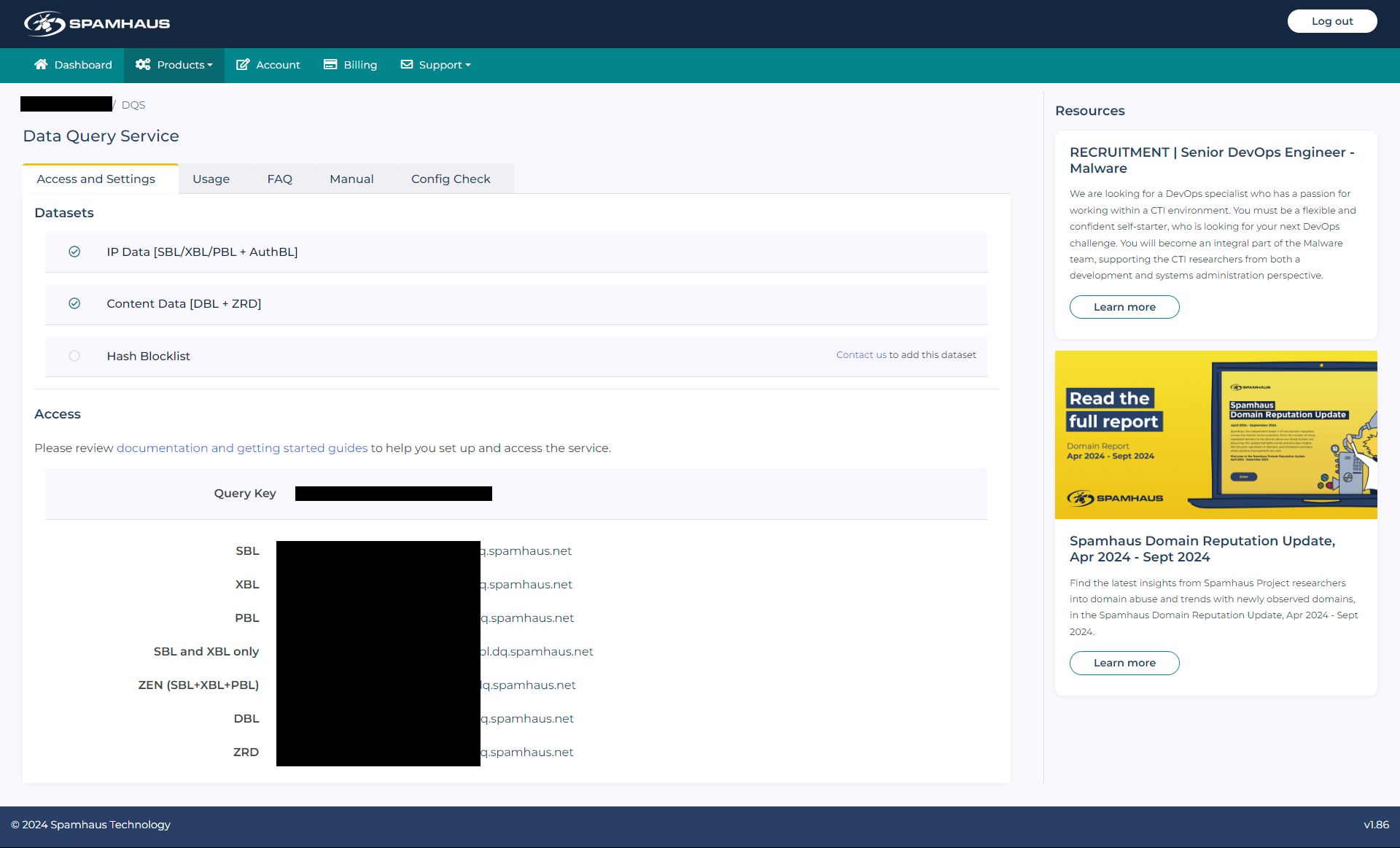
登録が完了したらダッシュボードにログインして、上のナビからProducs>DQSでキー入りの専用アドレスが発行さているのが確認出来るので、従来のzen.spamhaus.netの代わりにこのキー入りアドレスを設定してやれば引き続き利用出来る。
あとは、Postfixなら各種の拒否リストなどを設定する
smtpd_recipient_restrictions項目の先頭に
reject_rbl_client 鍵付き.spamhaus.net
を追加してあげれば良い。
通常、/etc/postfix/main.cfで設定。
|
1 |
smtpd_recipient_restrictions=reject_rbl_client キー.zen.dq.spamhaus.net,permit_mynetworks,permit_sasl_authenticated |
みたいな感じ
コレを設定すると、postfixの着信時にブラックリストを確認してくれる。
/var/log/maillog を読むと
|
1 |
NOQUEUE: reject: RCPT from unknown[101.126.80.244]: 554 5.7.1 Service unavailable; Client host [101.126.80.244] blocked using キー.zen.dq.spamhaus.net; Listed by CSS, see https://check.spamhaus.org/query/ip/101.126.80.244; from=<admin@xsn2uf8lfu3lih.top> |
みたいに、spamhaus RBLに登録されていたからメールキューに入れずに拒否したよ、とログが出る。
クライアントレベルならメールクライアントのフィルタで切ったり出来るけどサーバストレージを無駄に使われたくないので、設定しておくのが良い。
(172)
Google環境に色々な物を置いているけどセキュリティ情報をべた書きしたりするのは嫌なのでSecret Managerを活用するわけだけど、alembicってSQL接続情報をiniファイルに書くスタイルなので何とかならないかなぁと検討。
(36)
Cloud RunにSeleniumベースのテストサービスを構築した(先日のDocker作成)
で、本番環境で動かす時にこのサービスは非公開だけど非公開のRunって初めて構成したのでセキュリティをどうするのかと検討。
このサービスの呼び出し元はアプリビルド時の動作確認と、定期ヘルスチェックの2つ。 Cloud Build&Schedulerってことで、Google Cloud内部なのでIAMとかで簡単に構成できる気がする。
Cloud Runの設定でセキュリティタブに認証項目がある。
認証が必要
Cloud IAM を使用して承認済みユーザーを管理します。
うん、この設定ならIAMで認証できて中に認証とか組む必要ないね。
では、これはどう動くのか?
一言で言ってAuthorizationヘッダーで適切な権限のあるトークンが与えられることを確認している。
Schedulerの場合は簡単、スケジュールの設定で「実行内容を構成する」にあるAuthヘッダーの項目で「OIDCトークンを追加」を選択して「Cloud Run起動元」の権限があるSAを選択すれば勝手にやってくれる。
Buildの場合は、gcloudコンテナのbashエントリーポイントで gcloud auth print-identity-token を実行すればトークンが取得できる。
複数のステップで共有する場合はWorkspaceを使って保存して使い回すと早い(Googleのコンテナで/workspace/配下はビルド実行中に引き継げる一時ストレージなので、トークン取得ステップで
gcloud auth print-identity-token > /workspace/token.txt
とかすれば、以降のステップでは /workspace/token.txt を取得すれば良い)
一つのステップの中だけで完結する場合は変数に入れて、
token=$(gcloud auth print-identity-token)&&curl -H “Authorization: Bearer $token”
みたいな感じでAuthorizationヘッダを付加して叩いてやれば良い。 Googleのドキュメントにあるサンプルは大文字TOKENだけど、Buildでは$大文字はBuild自体が置換するのでそんなの無いよエラーを吐くので、小文字でなければならないところは注意。
BuildのSAに「Cloud Run起動元」の権限を付与しておく(今回はRunをデプロイするためにRun管理者のロールが付いていたので追加付与は不要だったが、Run以外をデプロイするだけのSAとかの場合は必要)
オンプレとかだと鍵認証とかを自分で組み込んだりする必要が出るけど、クラウドの場合はこういった権限管理の仕組みがあるから手軽に実現できて良いね。
開発段階でテストを実行したい場合・・・通常ならWebに対するテストは開発リポジトリにpushしたらトリガで開発にデプロイして、テストを起動して結果確認となるので、開発用Buildトリガを仕込んで、条件を開発ブランチにpushされた時にして、cloudbuild.yamlで普通に開発環境deployまで実行して、その後にテストを叩くステップを入れてやる。
deployまでだとビルドの結果はデプロイが成功したかっていう状態だけど、テストステップを追加すればdeployした結果テストが通ったかっていうアプリケーションレイヤーでの成功を一目で確認できる。
(35)
週末、相変わらずAIちゃんと戯れてみて実際に使える物を作るのはどんな感じかなと実施。
出来上がった物はこんな感じ
https://github.com/studioes/copilot-WoL-Flask
所要時間は環境設定込みで2~3時間と言う所でしょうか。
検索して情報・方法を得てコードを書くと言う部分が殆どCopilot任せになるので知らない技術を用いる場合には非常に有能に動いてくれます。 ○○について調べておいてって依頼するより遙かに早く結果が帰ってきます。
今回は自宅マシンをWoLするWebアプリケーションが欲しかったのでそれをCopilotとペアで開発しました。
最初のプロンプトは主機能であるWoL部分です。
>MACアドレスにマジックパケットを送信してWakeUpする処理
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Function to send a magic packet to wake up a machine by MAC address def send_magic_packet(mac_address): # Create a socket object sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # Set the socket options to allow broadcasting sock.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1) # Create the magic packet mac_bytes = bytes.fromhex(mac_address.replace(':', '')) magic_packet = b'\xff' * 6 + mac_bytes * 16 # Send the magic packet to the broadcast address sock.sendto(magic_packet, ('<broadcast>', 9)) # Close the socket sock.close() |
はい、マジックパケットの詳細は知りませんでしたが、ちょっと知っている情報からプロンプトを組んだら作ってくれました。 わずか数秒で。 普通ならGoogleでWoL magickpacket Pythonとか入れて検索して探して読んで・・・となって数百倍の時間かかるところが数秒です。 こういった所は非常に有能です。
そして追加プロンプト
>FlaskでWebから使える様に
Flaskの基本形が出来て/にGETならMAC入れるフォームが出来て、POSTなら先の物を呼び出す処理が出来上がりました。
ここからは機能を足したり、調整したりですが、ザックリ機能をつける場合はCopilotにお願いすれば入力時間より早く上がってきます。
>SQLAlchemyとsqliteでマシン名とMACアドレスを保存出来るようにして
>マシン名からMACアドレスを取得して保存出来るようにして
>Machineの編集、削除機能を作って
>Machineの一覧を作って、WakeOn、Edit、Deleteへのリンクを付けて
等の様にしてFlaskルート+処理実体が次々と出来上がりました。
他方で調整は解釈違いが起きるので人力の方が早いかなという印象。 これは普通にエンジニアがやっていても起きるヤツですね、要件者のイメージがうまく共有出来ないって言うヤツ。 なので、基本部分をCopilotで生成し人間が調整、調整したのをCopilotに学んで貰った上で、以後の調整を補完など支援して貰うって言うのが現状のベストかなと感じました。
ちなみに、README.mdについてもChatで「このプログラムのREADME.mdを作って」とお願いすると、それっぽく概要が出来上がってきて、いまいちだけど必要事項も入っていて、何も無いよりは良い、ちょっと待つだけでこの程度出来るなら十分。 という感じでした。
現状はVSCodeでやっていますが、PyCharmにもプラグインがある様なのであちらで整備してやりたい感じもします。 個人的にPyCharmの方が最初からPython用にカスタムされててデフォルトの機能も動きが良いのでVSCodeでも出来るけどPyCharmの方がなお良いと言う感覚があります。 また、JetBrains自身もAIアシストがあるようなので、Copilotと比較であちらも試すのもアリかなと(しかし、評価期間がCopilot30日に対して、JetBrainsは7日しか無い)
(58)
新しい勤務先がGoogle Cloudメインなのでそれになれる為に各種リソースをおさわりしています。
今回は無料枠があるけどあまり利用していなかったCloud Runを活用してサイト監視のシステムを作ってみました。
Cloud Runは、コンテナを走らせてくれる環境で、普通にDockerファイルを用意してやれば動きます。 今回は自分のサービスのハイレベル監視をこれで動かそうと言う事で、Seleniumによるアクセスを行うコンテナを作りました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
FROM ubuntu:24.04 WORKDIR /app EXPOSE 8000 RUN apt-get update && apt-get install -y \ python3 \ python3-pip \ wget \ unzip \ dbus \ libcups2 \ libvulkan1 \ xdg-utils \ libatk-bridge2.0-0 \ libgtk-3-0 \ libasound2t64 \ libu2f-udev \ libcurl4 \ fonts-liberation \ libgbm1 \ libnss3-tools \ fonts-ipafont-gothic \ fonts-ipafont-mincho \ fonts-noto-cjk \ language-pack-ja \ uvicorn RUN wget -q https://dl.google.com/linux/chrome/deb/pool/main/g/google-chrome-stable/google-chrome-stable_127.0.6533.99-1_amd64.deb && \ dpkg -i google-chrome-stable_127.0.6533.99-1_amd64.deb && \ apt-get install -f -y; \ rm google-chrome-stable_127.0.6533.99-1_amd64.deb RUN wget -q https://storage.googleapis.com/chrome-for-testing-public/127.0.6533.99/linux64/chromedriver-linux64.zip && \ unzip chromedriver-linux64.zip \ mv chromedriver-linux64/chromedriver /usr/local/bin/; \ rm chromedriver-linux64.zip; \ rm chromedriver-linux64 -r COPY src/ ./app/ COPY ./requirements.txt ./app/ RUN pip3 install -r ./app/requirements.txt --no-cache-dir --break-system-packages RUN apt-get purge -y --auto-remove build-essential python3-pip wget unzip make gcc lib*-dev RUN apt-get clean RUN rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* CMD /etc/init.d/dbus start&&export XDG_RUNTIME_DIR=/run/user/$(id -u)&&mkdir -p $XDG_RUNTIME_DIR&&chmod 700 $XDG_RUNTIME_DIR&&chown $(id -un):$(id -gn) $XDG_RUNTIME_DIR&&export DBUS_SESSION_BUS_ADDRESS=unix:path=$XDG_RUNTIME_DIR/bus&&dbus-daemon --session --address=$DBUS_SESSION_BUS_ADDRESS --nofork --nopidfile --syslog-only&sleep 1&&uvicorn app.main:app --host 0.0.0.0 --port 8000 |
Dockerfileはこんな感じになりました。
ベースはUbuntu24,04を使い、アプリは/appに配置することにしました。
Selenium+Chromeを中で動かすためにaptで結構色々ライブラリやら日本語フォントやら入れています。 Ubuntuミニマムだと数十MBのイメージがで来ますが、これだと1.5GB位(Artifacts Registoryの仮想サイズで600MB+なので無料枠を微妙にはみ出します)
開発環境はDockerとか諸々のツールが入ってるディレクトリの下にsrcディレクトリを切った状態で作業しているので、コンテナを作る時にはsrc以下をまるっとappにコピーしてます。 requirements.txtだけはsrcより上位にあるので追加コピーしてpipで入れて、コンテナサイズ節約のためにaptのパージとか適当にかけてます。
CMDで出すところが非常に長いです。 これは、Chrome使う時にdbusうごいてねーよって怒られたので、dbusを立ち上げた後にuvicornをスタートさせてるためです。 sleep 1は動かしてるインスタンスが小さいので安定のために待機させてます。
個人なら普通にローカルで作ってアップしてでも良いですが、やっぱり仕事の勉強がてらなので、ここはCloud Buildで継続デプロイも構成。 GitHubのマスターブランチにプッシュしたら走るトリガを作って、cloudbuild.yamlを準備。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
steps: - name: 'gcr.io/cloud-builders/docker' entrypoint: 'bash' args: ['-c', 'docker pull us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium:$BRANCH_NAME || exit 0'] - name: 'gcr.io/cloud-builders/docker' args: [ 'build', '-t', 'us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium:$BRANCH_NAME', '--cache-from', 'us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium:$BRANCH_NAME', '-f', 'Dockerfile', '.' ] - name: 'gcr.io/cloud-builders/docker' args: [ 'push', 'us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium:$BRANCH_NAME' ] - name: 'gcr.io/cloud-builders/gcloud' args: [ 'run', 'deploy', '--project', '$PROJECT_ID', 'selenium', '--image', 'us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium:$BRANCH_NAME', '--region', 'us-west1', '--platform', 'managed', '--max-instances', '1', '--min-instances', '0', '--memory', '1Gi', '--timeout', '3m', '--cpu', '1', '--concurrency', '1', '--port', '8000', '--allow-unauthenticated', '--service-account', 'Runが走るサービスアカウント' ] - name: 'gcr.io/google.com/cloudsdktool/cloud-sdk' entrypoint: bash args: - -ceux - | gcloud artifacts docker images list us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium --include-tags --filter="TAGS!=latest" --format="value(DIGEST)" | xargs -n1 -I{} gcloud artifacts docker images delete --quiet --async us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium@{} images: - us-west1-docker.pkg.dev/$PROJECT_ID/リポジトリ名/selenium:$BRANCH_NAME options: logging: CLOUD_LOGGING_ONLY |
最初のDocker PULLは2回目以降のビルドを高速化するために既存のコンテナを取ってきてキャッシュ利用するためのおまじないです。 このビルドだと初期は5分くらいかかりますが、これやると半分くらいで収まります。
で、DockerをビルドしてArtifacts Registoryにpush。
ターゲット系がus-west1で纏まってるのは無料枠が大抵このリージョンになるので合わせている都合です。 仕事では普通にasia-northeast1。
pushしたコンテナを使ってRunをデプロイしてます。
自分用ケチケチなので1Giメモリ1CPUで暴走課金防止のためにタイムアウトも3mと短め、Max-instace1でMin0なので結構コールドスタートになります。 今回はFastAPI側に認証機構を持たせるのでallow-unauthenticatedを指定してます。 内部から呼び出すだけの場合はこれを外して適当なIAM設定の所からコールするのが良いです。
で、サービスアカウント指定は、Runを呼び出すんじゃ無くRunが使うサービスアカウントなので、例えばCloud Storageに保存するならストレージ書き込みロール、Cloud Loggingに書き込むなら同様にログ書き込みロールを付けるだけで、Run実行などは不要です。 Google Cloudのサービス特に呼ばないならそれこそ何も権限が無い状態でも動きます、デフォのComputeは権限が凄く付いていて危なっかしいので、必ず権限を削った物を用意します。
デプロイ後に追加のgcloud sdk使った処理がありますが、こちらはArtifacts Registoryからlatest以外を削除してしまう処理です。 リポジトリ自体にもライフサイクル削除機能がありますが、最低1日1回走るって言う機能なので、テストで頻繁にpushしてると削除されるまでの時間でも結構なサイズが溜まってしまうのでデプロイの最後で消しています。 通常はRegistory側の設定だけでこれは不要ですね。
これで、src配下に置いたソース入りDockerがCloud Run上で動いてくれるので、あとはSchedulerなりなんなりで叩いて走らせます。
アプリ側は基本形はこんな感じでやってます
|
1 2 3 4 5 6 7 8 9 |
driver = None @asynccontextmanager async def lifespan(app: FastAPI): global driver with ChromeDriverFactory.create_driver() as driver: yield app = FastAPI(lifespan=lifespan) |
複数のAPI機能で唯一のchromedriverを使い回すためにグローバルにdriverを作り、コンテキストマネージャのライフスパンを使ってアプリ起動時にドライバを生成し、終了時に落とすためにwithでドライバ呼んで中はyieldのみという感じに。 ChromeDriverFactory.create_driverは各種オプション指定してChrome webdriverを作ってwebdriverを返してます。
後は各種APIを実装、グローバルに置いてるdriverを使い回していく感じ。
この構成でコールドスタートだと10秒くらいかかりますが、まぁ許容かなと。 Cloud Runは立ち上げからレスポンスを返すまでの課金ですが、インスタンス自体は即座に止まらずにアイドルで一定時間残るので、連続でリクエストを投げていく分にはそれほど問題になりません。 表示テスト、ログインテスト、編集テスト、編集結果反映確認テスト、削除テストと順番に投げていくと初回がコールドスタートで15秒とかかかるけど、その後のは2~3秒で進んでいって、サイトがちゃんと動くねテストが一通り30秒とかで終わります。 Cloud Schedulerも3ジョブまで無料(Githubに一つ取られてるのでウチの空きは2個だったので、テスト一式を起動するジョブを1本設定)なので、ほぼ無料で毎時にサイト動作確認とか出来ます。 ちょっとDockerファイルサイズがはみ出してる都合でArtifacts Registoryの課金が月に数円程度の感じ。
リソースのヘルスステータスはモニタ出来ますが、データ壊れておかしくなってるとか言うケースでは検知出来ないので、Selenium等の実際のUI操作テストは有用なので、程よいコスト感で回せるCloud Run+Schedulerのシステムは良い感じですね。
(270)
